Ch. 4: Data Processing
INTRODUCTION
GIS programs link attribute data files to digital maps. The previous Chapter focused on the map side of this equation. Let’s focus now on the attribute data files. Like the previous chapter, this chapter examines several key concepts and covers the preprocessing of your GIS data, but it specifically focuses on attributes, data files, and the editing of your attribute data. The concepts focus on attribute data and principles of raster and vector database management. Understanding these concepts will help you to effectively edit and manage your attribute data. The bulk of the chapter focuses on various preprocessing routines including adding and deleting fields, deleting records, joining data files, selecting and sorting records, calculating attributes, and geocoding. The chapter ends with a short discussion regarding attribute verification.
ATTRIBUTE DATA
As described in the previous chapter, spatial data occupies geographic space. It has a specific location that is tied to one of the world’s geographic referencing systems (like latitude and longitude). Besides spatial data, GIS files contain non-spatial attributes that describe the spatial features. This section focuses on these non-spatial attributes.
Related to the discussion of “measurements of scale” in Chapter 2, your attributes can be classified as either qualitative or quantitative and actual or derived. Quantitative data focus on numbers and frequencies rather than on subjectivity, meaning, and experience. They are easy to analyze statistically, and their values are often the result of field work and laboratory experiments. Maps exhibiting quantitative data depict differences in magnitude among features.
Qualitative data, by contrast, often provide deeper description and meaning. Maps displaying qualitative data show differences in kind or type. You might subjectively judge whether a quantity is low, medium, or high. You might also classify detailed land uses into broader categories of residential, commercial, and industrial. The statistical options are narrowed too due to the subjectivity of the data and the categorization of data into classes.
Data can also be defined by whether they represent some intrinsic characteristic of the feature being measured (absolute), or whether they are in a sense “created” (derived). Absolute data consists of both the quantitative and qualitative data just described, but it represents phenomena that are measured (like election data or the amount of water stored), the ranking and rating of attributes (even though this process can be subjective), and personal, subjective accounts gained from questionnaires and surveys.
Derived attributes either do not occur naturally, or they cannot be directly gathered; they are the result of statistical manipulation that produces the data. An example is average July temperatures, which is the calculated result of averaging many actual temperature values. Derived data may result from averaging actual values like these, or they represent the relationships between already gathered attribute data, which take three forms: ratio, proportion, and percentage.
- Ratio attributes are derived when the value of one attribute is divided by the value of another. Population density is a good example. The total number of people within a particular region is divided by the region’s area. Both the population and area attributes may be “actual” values, but the calculated population density attribute is derived.
- Proportion compares the value of one attribute to the total value of all related attributes. The proportion of all African-Americans to the total population is derived by dividing the number of African-Americans (actual data) by the total number of people (also actual).
- Many people think of proportions as percentages; they are similar, but percentages multiply proportions by one hundred.
PRINCIPLES OF DATABASE MANAGEMENT – VECTOR
Let’s turn our discussion from characteristics of data to how these values are organized within a data file. Data files are the basic “database” for many programs including spreadsheets, statistic programs, and GIS. Within a GIS, there is a data file for each particular type of geographic feature (e.g. streets, street lights, buildings, and parcels of land). They are the database’s version of your features. The data files are automatically created when feature layers are defined in your GIS. You place into them the attributes related to the features.
Data files, often called “tables,” arrange attributes within a matrix of fields and records. Fields form the columns of a data file (see Figure 4.1), and they contain the values for each specific attribute you are collecting. For example, parcels might include attributes such as area, land use, and Assessor’s Parcel Number (APN). In this example, you would have at least three fields: one called area, another titled land use, and one labeled APN.
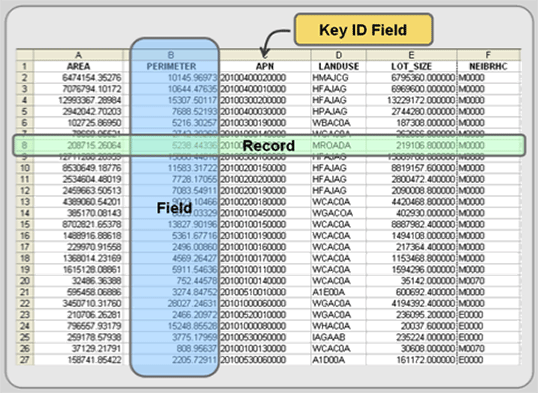
Figure 4.1: Key parts of a data file.
Remember from Chapter 2 that each of these fields has a specific “data format” that defines the type and length of the value that can be directly entered into the data file. Frequently attributes are coded as one of the following, but there are many data formats and the specific name of the data format often changes from one software program to another. Broad data format categories include:

Figure 4.2: Data format categories.
A single record, a row in the data file, represents the database’s version of a single feature, including all of its specific attribute values (see Figure 4.1). A few of these attributes may be system variables that the GIS needs for data integrity reasons and to link the data file to the feature’s spatial files. In addition, some GIS programs automatically generate length calculations for line features and both area and perimeter calculations for polygon features. Each data file should have a key identifier field that uniquely identifies each feature (i.e. each record). The remaining attributes are up to you and the purpose of your study.
Data files are a collection of related records. If you have 25 street lights within your GIS, you will have 25 street light records in its attribute file. As briefly described above, a largely empty data file is created when a new layer is defined within a GIS program. It is your job to add fields and attribute values to the data file. These descriptive attributes can be entered by hand or imported from external sources. It is likely that you will enter some attributes by hand (and it can be time consuming and tedious), but many—if not most—of the attributes you seek will be imported or “joined” from separate, non-GIS data files. This is because many non-spatial data files predate your need for their incorporation into a GIS, but it is deeper than that. Data manipulation within GIS is clumsy, and since most GIS users are familiar with data management programs like Excel and Access, they prefer working with these programs and then exporting their data and “joining” the external data file to the GIS data file. The joining process is described later in this chapter.
These external data files are coded in one of many “file formats”. Some file formats are specific to a particular software program while others are somewhat universal. Even those using a program’s proprietary format can export the data file into one of many formats that most GIS programs can read. Some of the file formats that can be read by most GIS programs include:
dBase This industry standard format is read by just about every GIS program. Many GIS programs use this format internally rather than creating their own.
Excel and Access – Microsoft’s file formats for Excel and Access can be read by many GIS programs. If your GIS program does not read these formats, open the data file in Excel or Access and export it into a format that your system reads.
ASCII (American Standard Code for Information Interchange) – Since most computers use ASCII to represent text, it is possible to transfer data from one computer to another in this format. It is also read and written by most GIS programs, but it is rarely used as the primary GIS file format (with the exception of some raster-based GIS programs). Some government data sets are contained in this file format. Text files come in several different “delimited” forms, and all may include numeric or alphanumeric content (see “Joining Data Files” later in this chapter).
Data files contain a matrix of fields and records for each feature layer. A database is a collection of several related data files (like parcels, street lights, and buildings). In other words, databases contain data files for related layers. Accessing these data files are done through either the GIS software or increasingly from external database management systems (DBMS) that are linked to the GIS. DBMS are specialized programs that organize, manipulate, and report non-spatial data and help you store your data more efficiently. They are particularly valuable when working with large data sets because you can select a subset of your records and fields to work with. The entire attribute file does not have to be used. Examples of external DBMS programs include Access, Oracle, Ingres, SQLServer, INFORMIX, and to a lesser degree Excel, which can serve as an elementary database program. Regardless of whether you are accessing the data files within the GIS software or from an external DBMS, all databases have standard operations which include sorting and selecting records, deleting records and fields, and editing fields and attributes.
Different databases have different structures or ways to organize data. The hierarchical and network data models are two examples, but they are rarely used for GIS (and so will be skipped in this section). For vector systems, the relational database model is the most common data model arguably because they are more flexible, the table structure is easy to understand and program, and outside of GIS, data files are commonly held in relational databases.
Linking or joining data files is the relational database model’s strength. Key identifiers, found in multiple data files, are used to link records from one data file to another. In other words, you cross reference multiple data files using common attributes and attach (or join) these external data files to your internal GIS data file. This link takes the selected fields in the data file you wish to join and relates them to the appropriate records in the GIS data file. This requires that each data file have at least one common field to perform a join. There are different names for the key identifier including key and primary key. This process is highlighted later in this chapter.
Many, however, think that the relational database model does not adequately represent spatial data. For some, records in a relational data file are too discrete; they do not properly depict the continuous and multi-dimensional nature of the features they are representing. We use relational data models because they are simple and convenient, but we artificially bend geographic features to conform to existing database standards that were created for non-spatial data.
This has led to the development of object-oriented data structures, which are seen as a more sophisticated database model. The database discards many of the foundational concepts that we have applied throughout this book. Features are defined differently; object-oriented features blur the line between points, lines, and polygons. Also, instead of having multiple files for each GIS layer, the geography and attribute data are integrated into a single file. This allows for simultaneous geographic and attribute editing and quicker processing. The more sophisticated model, however, is a more complex model, and that may have slowed its spread even though “object-oriented” databases were one of the hottest topics in GIS in the 1990s. It may still be the touted successor of the relational model, but it seems that the relational model, despite its drawbacks, has significant pluses—including its ease of use—that will help it dominate at least into the near future.
PRINCIPLES OF DATABASE MANAGEMENT – RASTER
As described in Chapter 1, the raster data model aligns the Earth’s surface into a grid of columns and rows. Cells, or pixels, the building blocks of the raster data model, form at the intersection of the columns and rows, and each cell contains a single attribute value, representing the condition of a specific portion of the Earth’s surface. That means that a single raster layer only contains the values for one specific attribute across space. That last point is important because raster layers fill space. Their attributes occur everywhere in the study area; there are no blank spaces. Empty areas get a “0” value, but every pixel gets a value. If you need more than one attribute, you construct multiple layers, each containing a single specific attribute for the same area. Conceptually, it is a simple model. As in Figure 4.3, your study area is divided into cells, and each cell of each layer has a single attribute that represents that area.
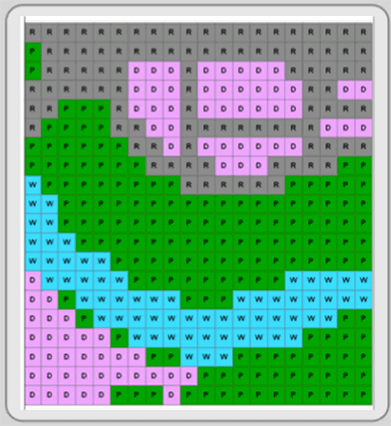
Figure 4.3: Raster image. Image by Mike Tuck.
There are many ways—some more complex than others—the raster data model may be stored. The two general categories are regular and irregular. The regular structure is conceptually simple, and includes two types: full raster encoding and run-length encoding. Full raster encoding creates a data file that records the attribute value for every pixel. It’s as though you read an image’s pixels like a book, starting in the upper left corner and reading from left to right and downward row by row. The data file looks a bit different. It records each pixel’s attribute value on a separate line, so if you had an image with 640,000 pixels, your data file would have 640,000 lines, making it a very long data file. Figure 4.4 is a simplified example.
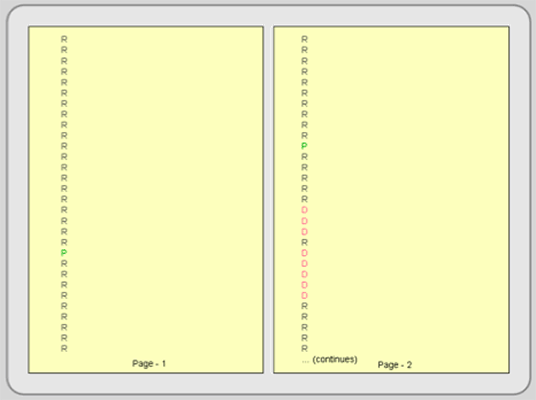
Figure 4.4: Full raster encoding. This figure is the beginning—just the first three rows—of the data file for the image in Figure 4.3. Color is added to highlight the different attribute values.
Run-length encoding is more efficient than full raster encoding. Since the same values often occur in runs across several cells, run-length encoding enters the attribute values as pairs: the first number is the run length and the second number is the cell’s value. This substantially reduces file size especially if contiguous pixels have the same value. Contrast Figure 4.5 with Figure 4.4.

Figure 4.5: Run-length encoding. This figure also depicts the first three rows of Figure 4.3. Compare run-length encoding with full raster encoding (Figure 4.4). Color is added to highlight the different attribute values.
Irregular raster data structures, like quadtree and others, are more complex, proprietary, and beyond the scope of this e-text. They usually make file size smaller and provide ways to store raster data for quick retrieval.
ATTRIBUTE PREPROCESSING AND EDITING
When you add feature layers, containing both spatial and attribute data, to an active workspace, the attribute data file might not be immediately visible. Opening and editing the attribute files are easy processes, but they are specific to individual programs. Once the attribute table is open, you can enter data by typing attribute values directly into the data file or loading and joining external data files to it. Other processes like editing attributes, adding or deleting fields, deleting records, querying attributes (record selection), calculating fields, and geocoding are completed through the data file interface.
Adding and deleting fields
As described above, fields define feature attributes. Most GIS programs provide a way for you to add or delete fields from within your open data file. The GIS program will instruct you to define a new field. You will give it a name and select from options that determine the data format of the values that will be placed into the field. Deleting a field usually involves selecting the field and deleting it.
Deleting records
You can delete a single record or a group of records in a data file by first selecting them and then deleting them. Since records are the database representation of features, when you delete records in the attribute file, you are also permanently discarding their spatial representation. The entire feature, graphic and record, is deleted.
Generally, you can not add a record through the data file interface because it must also be represented spatially. See Chapter 3 for how to add a feature. Its record is automatically created when the graphic feature is added to the workspace.
Joining Data Files
Once a GIS layer is created, its attribute file can be linked (“joined”) to external data files. Joining is one of the most frequently performed data file processes because it brings together feature attributes that are contained in multiple digital data files. To perform a join, a unique matching field, the key identifier, must be observed in both data files. As stated in Chapter 3, the key identifier could be something like a social security number or an assessor parcel number. It is a field that gives the feature a unique identification. Once linked, the join can be temporary or made permanent.
The external files that you load into the GIS to perform a join are typically in file formats such as dBase, ASCII, Microsoft Excel, or Microsoft Access. The precise steps involved in joining together two files are software specific, but it usually involves:
- loading the external file that you wish to join to the GIS attribute file,
- selecting the external file and the GIS attribute file that you wish to join,
- selecting the field (containing the key identifier) in each file, and when joined,
- making sure that the join was successful.
In the example in Figure 4.6, the parcel layer exists, but it does not include assessed value. It does contain a field named APN (Assessor’s Parcel Number) whose values are unique to each record and which could be used to join other data files. A spreadsheet file, with assessed value, also exists, and it must be loaded into the GIS either in its native format (if accepted) or exported from the spreadsheet program to a format that the GIS can read. The spreadsheet has a field named APN_NUM, which, after a visual check, has the same values as those under APN in the parcel layer, and it can be used to perform the join.
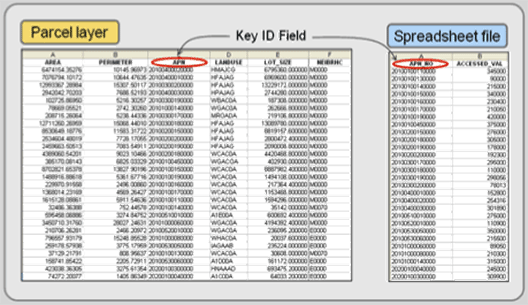
Figure 4.6: Joining two attribute files together requires that the two files each have a common key identifier.
Once the spreadsheet file is loaded, you begin the joining process by specifying the two files (the layer’s table and the spreadsheet file) and the two field names that the join will be made on. APN and APN_NUM are the key identifiers of these two files (see Figure 4.7), and even though the field names are not identical, the GIS will be able to join these two files together provided that the values under the two field names match.
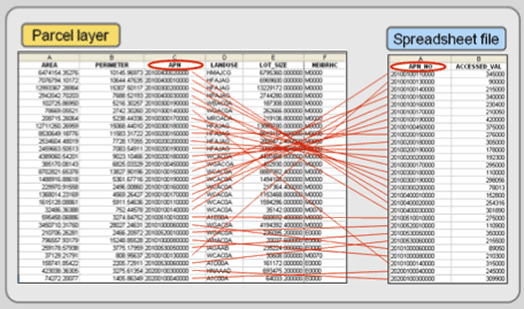
Figure 4.7: Matching key identifiers.
If the match is successful, your two files will be joined together into a single file (see Figure 4.8).
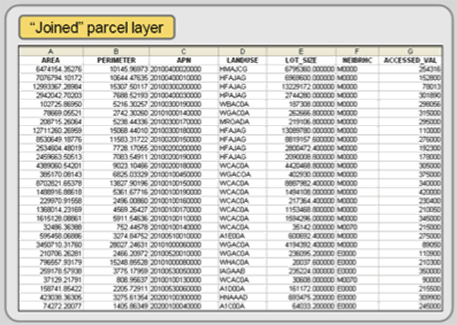
Figure 4.8: A joined file with accessed values a one of the attributes.
Perhaps the most time consuming tasks are the first and fourth steps. Loading an external data file should be easy —and frequently it is—but sometimes the imported data file may be misformatted or unreadable. If it is, return to the host program (your spreadsheet or DBMS programs) and save it in a different format. The probability of your GIS program being able to read the external data file usually improves as you go from more sophisticated file formats (like Excel and Access) to dBase to ASCII (basic formats). Many data files are coded in ASCII because of its almost universal compatibility with computers and software programs, but it does have its complications—it comes in several forms. Below are four of the most used variants of ASCII based on what delimits the file’s fields.
Whitespace delimited ASCII files differentiates fields by the use of one or more spaces. Since spaces separate fields, fields that have no value must be represented by a non-blank code and character attributes cannot contain spaces between words (underscores can be used to separate words). You can open ASCII files in any word processer or text editor. A whitespace-delimited ASCII data file with five records might look something like the following:
M1 Betsy_Burns Yes 38.5 0.85
P1 Dan_Arreola No 45.7 0.99
M2 Frank_Aldrich Yes 32.8 0.55
P2 Fritz_Steiner No – –
P3 Ruth_Yabes No 37.72 –
Spacequote delimited ASCII is a variant of whitespace delimitation, but the attributes containing multiple words are enclosed in double quotes, and consequently, they can contain embedded spaces between words. The spacequote delimited ASCII file may look like the following in a text editor:
M1 “Betsy Burns” Yes 38.5 0.85
P1″Dan Arreola” No 45.7 0.99
M2 “Frank Aldrich” Yes 32.8 0.55
P2 “Fritz Steiner” No – –
P3 “Ruth Yabes” No 37.72 –
Tab delimited files separate fields by the use of a single tab. Two tabs in a row signify a blank field. Values within an attribute field cannot contain embedded tabs. A tab delimited ASCII file would look like the following in a text editor.
M1 Betsy Burns Yes 38.5 0.85
P1 Dan Arreola No 45.7 0.99
M2 Frank Aldrich Yes 32.8 0.55
P2 Fritz Steiner No
P3 Ruth Yabes No 37.72
Comma delimited, also known as comma-quote delimited and CSV, separate fields by commas. Character fields may be enclosed in double quotes, and need to be if they contain an embedded comma. Two commas in a row signify that the field is blank. Usually whitespace is not allowed before or after fields (although this may be tolerated in the CSV form). The comma-delimited ASCII file might look like the following in a text editor:
M1,”Betsy Burns”,Yes,38.5,0.85
P1,”Dan Arreola”,No,45.7,0.99
M2,”Frank Aldrich”,Yes,32.8,0.55
P2,”Fritz Steiner”,No,,
P3,”Ruth Yabes”,No,37.72,
Sorting records
Sorting temporarily rearranges your data file records, so you can view, select, update, or print them in the new sorted sequence. Although the specifics vary by program, you generally choose the field (or fields) you want to sort by. The first sort field arranges, usually in ascending or descending order, the records based on the field’s contents. For example, a class roster might be sorted alphabetically by last name. Some systems allow you to choose a second sort field (or more), which arranges records (in ascending or descending order) when two or more records have the same first field value. In the example above, if your alphabetical list has four students with the last name Smith, those four records could be rearranged in alphabetical order based on their first name.
Record selection/Attribute Query (Boolean Selection)
Selecting specific records is one of the most common database functions. Often called attribute query, it consists of highlighting a subset of the records based on a specific criteria. In other words, you create an expression—a formula—that queries all the records in the data file and the GIS highlights—both in the data file and on the map display—only those features that fit the criteria.
Most GIS programs use a Standard Query Language (SQL) interface to conduct attribute queries. If one is using an external relational DBMS program (like Access or Oracle), SQL makes the call to the external database and isolates only the necessary records that you will use. SQL uses set algebra, Boolean algebra, and arithmetic operators (=, -, *, /) for attribute queries. Set Algebra includes the use of less than (<), greater than (>), equal to (=), and not equal to (<>) operations. You can create an expression like that found below (see Figure 4.9) to isolate only those records that fit your criteria. You can extend or constrain the selected features by using Boolean algebra, which uses the conditions OR (extend), AND (constrain), and NOT to further select or isolate records. Each record is queried and added to the set if it meets the criteria.
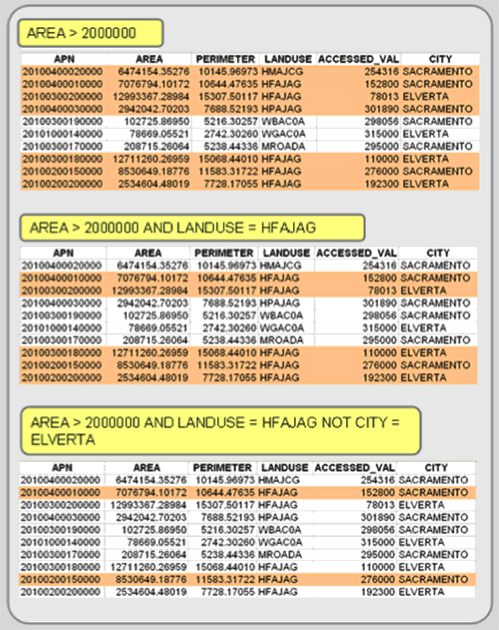
Figure 4.9: Select records based on their attributes by using SQL expressions.
Once the records are selected, you can work with just those records. This is helpful for viewing, sorting, editing, calculating fields, generating statistics, using the selected features to select features in another GIS layer, creating a new layer with only the selected features, and isolating specific records to perform analysis functions on (like buffering selected features).
In addition, spatial queries, selecting features based on their geographic location (see Chapter 5), can be combined with attribute queries for more sophisticated queries. There is more on attribute and spatial queries in Chapter 5.
Calculate Attributes
Within an open data file, you can create new attributes by using values in existing fields, mathematical expressions, and text functions (see Figure 4.10). Mathematical operations allow you to add, subtract, multiply, and divide existing fields or values to create new, derived attributes. Text functions allow you to populate fields with data, copy values from one field to another, concatenate fields (and or values), truncate attributes, and convert text to different formats. Before calculating the new field, however, you need to create a new attribute field, which includes defining its field name and its data properties). Calculations can be performed on a single record, several selected records, or on every record in the data file. The calculate function can also be used to copy data from one field to another.
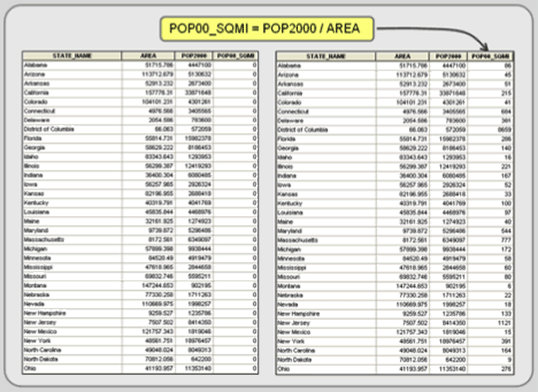
Figure 4.10: Calculating fields. In this example, population density is calculated by dividing population by area. First, the field must be added. Then, you calculate the results directly into the new field.
Geocoding
There is a way to create geographic data directly from attribute data. The process, called geocoding, assigns geographic locations to features directly from attribute fields that contain locational information within a data file. This is a popular way to create GIS feature layers; you create or obtain a spreadsheet or data file with location information, open the attribute table in your GIS, and direct the system toward the appropriate attribute fields. There are two types of geocoding: coordinate locations and address matching.
Spatial features can be created from data files containing fields with x,y coordinate values. The coordinates need to be separated into two separate fields: one for the x coordinate and one for the y coordinate. The process is straightforward; you direct the GIS to the data file’s appropriate x,y fields, and it creates a spatial layer of point features from the coordinates. One possible complication is that the data file’s coordinates are different than the coordinate system you are using. This requires that you open the file in a temporary workspace registered to the data file’s coordinate system and then convert the new spatial layer to the desired coordinate system.
Address matching is another type of geocoding. It matches records in two data files—one containing a list of addresses and the other having street network attributes—to create a new layer (see Figure 4.11). In other words, it creates a layer of point features alongside street segments when addresses in the two data files match. It essentially looks up the address in the first record of the external data file and tries to find a match along the street network layer. If multiple possibilities exist, the routine will present them for user input. After the first record is matched or not, it moves to the second record and tries again. The resultant file is assigned the street network’s coordinate system.
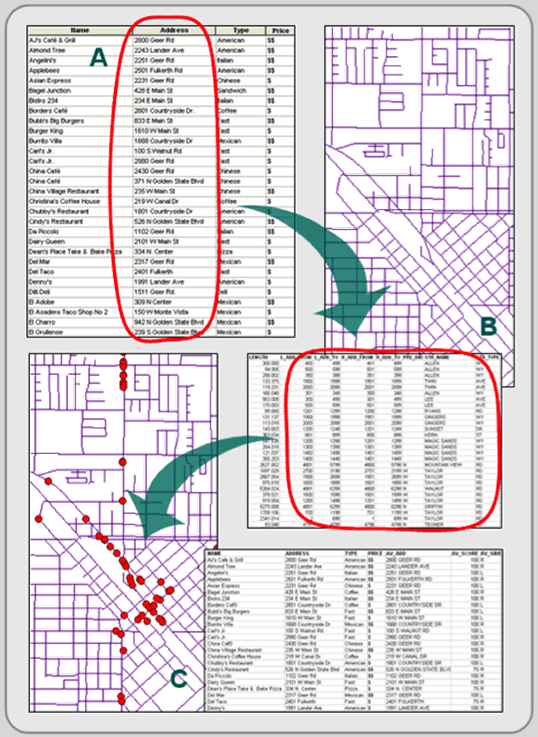
Figure 4.11: Address matching. The addresses in an external data file (A) are compared to a street network's (B) attribute fields, and if a match is made, the record in the external data file gets a point on the map (C).
Both the street network layer and the external data file need address data (street name, street type, and an address range for start and end of each line segment), and perhaps even more information like city, state, and Zip code attributes to make your address information unique (multiple cities will likely contain streets with the same name). The process works well if the addresses in both the external data file and the street network layer are accurate and complete, but address matching is a time consuming process.
Data Export
Exporting your GIS layers, including their geographic and attribute data files, are covered in Chapter 6. Most GIS programs can export your layer’s attribute file in a number of formats including dBase and ASCII. The exported files can then be used in database, statistic, and spreadsheet programs for additional analysis.
ATTRIBUTE VERIFICATION
This section looks at verifying the accuracy of attributes. The verification process looks for both missing attributes and incorrect attribute values. Unlike geographic verification, there are no attribute verification procedures built within the software to verify their accuracy.
Instead, the layer’s data file can be displayed and sorted by each attribute in ascending order to identify missing attributes (see Figure 4.12). Map features missing a value for a particular field are revealed at the top of the table. Selecting those features from the data file and highlighting them on the screen can be a handy way to reference those features that have missing attributes. The selected features can then be investigated and updated. You can also sort the attributes alphabetically and glance down the field looking for spelling mistakes.
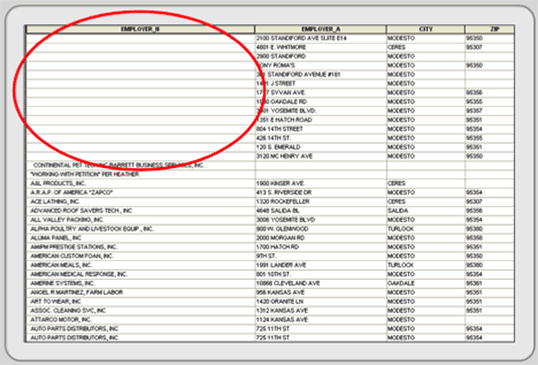
Figure 4.12: Sorting in ascending order can reveal missing data.
More difficult to detect are incorrect attribute values. They require familiarity with the original source maps and an understanding of spatial patterns. For example, if you were working with income data, you should select low income values and display them on a map. Does their spatial location make sense? Do the same with high income values. Nominal data sets can be displayed the same way. For example, select different land use classes, and see if they make geographic sense. Display all heavy industrial sites and look at their locations. If heavy industry appears in the middle of wealthy residential areas or they are not located along highways, railroads, or rivers (which they need for transportation purposes) than these values may be inaccurate. More information may be needed; try looking at web-based aerial photographs or field check odd values.
